Downloading Paul Graham's Essays
Puppeteer
2023
Typescript
Dyl
—
September 28, 2023

Introduction
This post accompanies some Typescript/Puppeteer code I wrote to download the entire essay catalog of Paul Graham in PDF form. If you don’t know who Paul Graham (PG) is, he’s the somewhat legendary co-founder of Y Combinator and Hacker News. Having been so heavily involved in the tech startup arena for the last two decades, Paul is somebody who’s worth listening to if you are interested in technology entrepreneurship.
PG also happens to be a prolific essayist, which is the reason why I created this post. Dating all the way back to 2001, PG has shared over 200 essays on his personal website (a no-frills static blog that presumably hasn’t changed in appearance since 2001). The Founders podcast did a couple of great episodes which are a good introduction to the writing of PG, if you want to see what the hype is about that’s a good place to start.
As somebody who takes a lot of flights (more than I would like), I always have reading material downloaded on my Kindle for offline use. Originally, I manually downloaded 10 of the essays. After reading maybe 3 or 4 of these, I decided to write some code to download the full collection of essays from his website - code which I’ve shared below.
Overview
The task I set out to complete was to create an automated script for downloading all 200+ PG essays as PDF files. The full essay catalog is listed on the articles page of PG's website:
Before we jump into the code, let's look at the high level steps that our automated script will need to follow:
- Programatically open a web browser (using Puppeteer)
- Visit the articles page to get a list of urls for all PG essays
- For each essay url:
- Visit the web page
- Save the page contents as a PDF file
If the script is re-run, it first determines which essays have previously been downloaded and skips downloading these. So only newly added essays are downloaded. When writing any kind of web-scraper/crawler, it's good practice to limit your impact on the websites you interact with.
When all essays are downloaded in PDF format, they can be quickly merged into a single file with a free online PDF-merge tool, before I email the file to my kindle's email address.
Puppeteer
Puppeteer is a NodeJS library that allows you to programatically control a web browser:
- Puppeteer is commonly used for automating all sorts of browser automation and testing tasks.
- The Puppeteer API let's you do most things a real user could do a browser, including visiting and interacting with pages (clicking buttons, filling in forms etc).
- By default Puppeteer uses the Chromium browser, which is a lightweight version of Chrome.
- The browser can be launched in headless mode, which doesn't require a full graphical UI to be spun up. This feature comes in useful when running Puppeteer scripts in low-resource environments, like CI/CD pipelines or Lambda functions.
For now, all you need to know is that we'll be using the Puppeteer library to interact with PG's website in our Typescript code. We'll need to navigate to pages (by URL), use CSS selectors to parse some metadata from the HTML (like essay title, publish date) and save the page contents as a PDF.
Alternatively, I could have used traditional web scraping libraries (i.e. with a http request library and something like Cheerio to parse the returned HTML). However, I'm experienced working with Puppeteer and the save as PDF feature is perfect for my use-case.
Without further ado, let's jump into the code.
Code
I won't go into the full implementation of every function here, but the full code (Typescript) is available on github. Also, this isn't a tutorial for the Puppeteer library; the documentation is excellent and there are already plenty of great tutorials for using Puppeteer available on the web.
Below is the entrypoint for the script. We have broken down the logic into five logical steps:
(async () => {
// 1. Initialize a Puppeteer "Browser" object
const browser: Browser = await getBrowser();
// 2. Get the urls of all PG essays
const allEssayUrls: string[] = await getAllEssayUrls(browser);
// 3. Filter out essay urls that we don't need/want to download
const essayUrlsToDownload: string[] = getEssayUrlsToDownload(allEssayUrls);
// 4. Visit and download all essay urls
await downloadEssays(browser, essayUrlsToDownload);
// 5. Clean up the Puppeteer/Chromium resourses created
await browser.close();
})();
Step 1: Initialize the Browser
// 1. Initialize a Puppeteer "Browser" object
const browser: Browser = await getBrowser();
We first need to create a Puppeteer Browser object, which we will use to programatically control our Chromium browser instance. We will be using a single Browser instance for the entire lifetime of our script:
// Instantiates a Puppeteer Browser, with Chromium browser as default
async function getBrowser(): Promise<Browser> {
const browser: Browser = await puppeteer.launch({
headless: true, // Change to false if you'd like to see the Browser window when the script is running
args: [`--window-size=1080,1024 --Mozilla/5.0 (iPhone; CPU iPhone OS 16_5_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.5 Mobile/15E148 Safari/604.1`],
defaultViewport: {
width:1080,
height:1024
},
});
return browser;
}
Step 2: Retrieve the Essay Urls
// 2. Get the urls of all PG essays
const allEssayUrls: string[] = await getAllEssayUrls(browser);
In this step we visit the /articles page and extract the list of urls for all the essays. First, we create a Page on the Browser object (like a tab) and use page.goto() to navigate to the articles page. Next, we use Puppeteer's Query Selectors to interact with the DOM and extract the list of all urls or links on this page:
const page: Page = await browser.newPage();
// Visits the essays index page and determines the list of all essay urls
await page.goto('http://www.paulgraham.com/articles.html', { waitUntil: 'networkidle2' });
const hrefElements = await page.$$("font > a");
const allUrls: string[] = await Promise.all(
hrefElements.map(async (he) => he?.evaluate(e => e.href))
);
Because we've extracted the links for every url on this page, we need to do some filtering to only get the essay urls that we want. In this filtering process I remove external links, duplicate essay urls and exclude some essays that were not interestin:
// Filter out any urls that link to a different website
const pgUrls = allUrls.filter(url => url.startsWith("http://www.paulgraham.com/"))
// This is a list of some urls/essays that I noticed were not interesting
// identified by their url suffixes, these essays will not be downloaded
const unwantedEssaySuffixes = [
"rss.html",
"index.html",
"fix.html",
"noop.html",
"rootsoflisp.html",
"langdes.html",
"lwba.html",
"progbot.html"
]
// Filter out essay urls if they have one the unwanted url suffixes
const keepUrls: string[] = pgUrls.filter(url => {
return unwantedEssaySuffixes.every((suffix) => !url.endsWith(suffix))
});
// Remove duplicate essay urls
const uniqueUrls = Array.from(new Set(keepUrls));
return uniqueUrls;
}
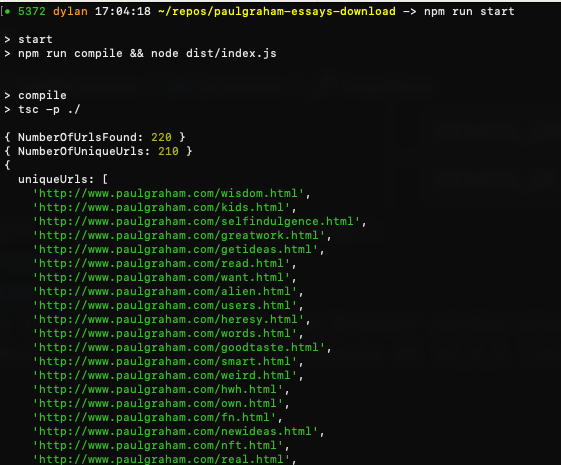
If you log the uniqueUrls return value, you'll see the extracted list of essay urls:
Step 3: Filter Essay URLs
// 3. Filter out essay urls that we don't need/want to download
const essayUrlsToDownload: string[] = getEssayUrlsToDownload(allEssayUrls);
This step is straightforward. We simply scan our /essays folder to determine which essays to downloaded (i.e. new essays). When the script is first run, the /essays folder will be empty and all essays will be downloaded. If the script does not find any new/missing essays it will not download any essays:
// Filters essay urls to exclude any essays that have already been downloaded
function getEssayUrlsToDownload(essayUrls: string[]): string[] {
const existingEssayIds: string[] = getExistingEssayIds();
const essayUrlsToDownload: string[] = essayUrls.filter(url => {
return !(_.includes(existingEssayIds, getIdFromEssayUrl(url)));
});
return essayUrlsToDownload;
}
Step 4: Download Essays
// 4. Visit and download all essay urls
await downloadEssays(browser, essayUrlsToDownload);
Now it's time for our script to actually visit all of the essay urls and download the contents:
async function downloadEssays(browser: Browser, essayUrls: string[]) {
const page: Page = await browser.newPage();
// One-by-one calls 'downloadEssay' for each url provided
// I have chosen not to use parallelization and a 4 second delay
// is added between each download (to be nice to PG's website)
await Bluebird.mapSeries(essayUrls, url => {
return Bluebird.delay(4000)
.then(() => downloadEssay(page, url))
});
}
As mentioned in the overview, it's good practice to write your webscraping scripts in a way that reduces the impact on the website you are interacting with. In this case, I'm sure PG's website can handle the traffic, but in general services like cloudflare are often used by websites to detect and block bot traffic from scraping their content.
I can run this locally on my Macbook, so I don't need to parallelize/optimize for run-time. I've purposely chosen to visit and download each essay sequentially, with a four second delay between each navigation.
Let's look at the implementation of the downloadEssay() function:
// Visits and downloads a single essay page (by url)
async function downloadEssay(page: Page, essayUrl: string) {
await page.goto(essayUrl, { waitUntil: 'networkidle0' });
// Use the url slug as essayId, e.g. `http://www.paulgraham.com/getideas.html` -> "getideas"
const essayId: string = getIdFromEssayUrl(essayUrl);
// Parse the essay title and publish year/month values
const titleElement = await page.$('body > table > tbody > tr > td:nth-child(3) > table:nth-child(4) > tbody > tr > td > img');
const title = await titleElement?.evaluate(el => el.getAttribute('alt'))
const [month, year] = await getMonthAndDateFromPage(page);
...
}
Page.goto() is used to navigate to the essay url passed. Once the page contents are completely loaded, we once again use the Query/CSS selectors to extract information from the page. This time, we are parsing metadata about the essay from the HTML contents. The metadata we want is the title of the essay and the publish year/month. These values are at the top of each essay page:
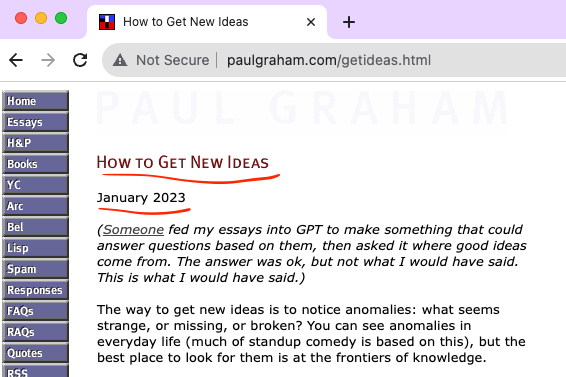
If you're not familiar with CSS selectors and DOM traversal, this line:
const titleElement = await page.$('body > table > tbody > tr > td:nth-child(3) > table:nth-child(4) > tbody > tr > td > img');
might look like gibberish to you. If you want to learn more about how this works I would recommend this Youtube Video and the excellent cheatsheet available in the video description.
Finally we save the page contents as a PDF, using the Page.pdf() method:
// e.g 'essays/2023/greatwork-2023-07.pdf'
const outputFilename = `${downloadDir}/${essayId}-${year}-${MONTH_MAP.get(month)}.pdf`;
// Create the download directory (if it doesn't already exist)
if (!fs.existsSync(downloadDir)){
fs.mkdirSync(downloadDir, { recursive: true })
}
// Download/save the page contents as a PDF
await page.pdf({
path: outputFilename,
margin: { top: '50px', right: '25px', bottom: '50px', left: '25px' },
printBackground: true,
format: 'A4',
});
Essays are saved in the /essays directory, with subdirectories for each year:
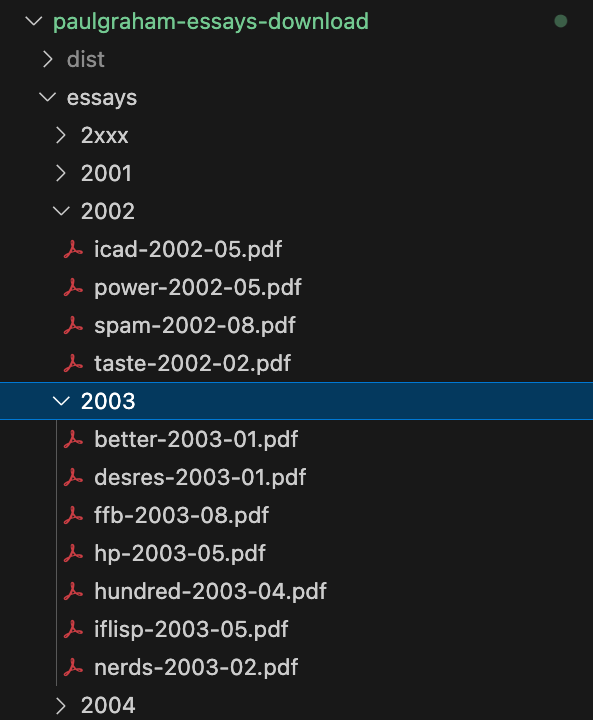
Parsing HTML page contents with CSS selectors is notoriously brittle and error prone. If the HTML structure of the page changes ever so slightly, it can cause the code that parses value (like our metadata) to throw an error. To account for this, I've created default values for the parsed year/month values. If the script encounters any problems parsing these values on an essay the essay will still be downloaded, but into the 2xxx directory:
Step 5: Cleanup
Finally, we need to cleanup the Chromium browser instance that we created:
await browser.close();
Running the Script
I've chosen not include the essay PDFs in this repository, as the essays are PG's content (not my own). Here are the simple steps if you want to get the essays for yourself:
- Clone the code from my github repo:
git clone git@github.com:DigUpTheHatchet/paul-graham-essays-public.git
- Install the node dependencies:
npm install
- Run the script:
npm run start
As is, the script will take a couple of minutes to run. This duration can be greatly decreased by parallelizing the downloadEssays() function.
You now have your own personal archive of PG's essays available for offline consumption!
Unfinished Work
I was going to title this section as Future work, but I don’t have any further plans to continue working on this. Originally, I intended to have the script running on an automated schedule, without a human in the loop.
However I've decided to use it as, manually running the script once or twice a year to pick up the new essays, for two reasons:
- PG publishes pretty infrequently now, so this infrequent cadence should work just fine.
- His essays are usually timeless, rather than timely, so there’s no need to have new essays delivered to my kindle as soon as they are published.
Improvements
If you wanted to polish this up a little further, some ideas are:
- Progamatically merge the downloaded PDF files:
- Rather than manually merging PDFs, utilize something like the pdf-merger-js library.
- Deploy the script as an automated/scheduled workflow:
- Instead of running this script locally, we could easily deploy it to run as an AWS Lambda Function.
- Because of headless mode, Puppeteer works well in a Lambda runtime enviroment (without GUI resources).
- I extensively used Puppeteer in automated workflows on Lambda/GCF in my previous role at Rezdy. There are some considerations that do need to be accounted for however (e.g. the dependency bundle size) when running Puppeteer in Lambda/GCF.
- Instead of saving files to the git repo, they would instead be persisted in an S3 bucket.
- The Lambda Function could then be scheduled to run weekly, saving any newly published essays to the s3 bucket.
- Automatically send any new essays to kindle:
-
Once the script is deployed as a (scheduled) Lambda Function, it could programatically send any new essays to your Kindle (e.g. using SES).